Documentation
Transfer optimization
Avoiding unnecessary files
If you think about the process occurring in the background as runaway performs an execution, you can see an immediate pitfall concerning data transfer. Indeed, when runaway sends the data, the entirety of the current directory is sent to the remote, including:
- All the
gitrepository - Every python cache files
*.pycthat may exist - Other data depending on the case !
Moreover, the same thing happens again when the data are fetched from the remote. Hopefully, runaway has a way to handle that. You can write send-ignore and fetch-ignore files, with the same globs you would use in a git repository. By using those two files, you can specify files to send and fetch in various ways:
| Only send-ignore exists | Only fetch-ignore exists | Both exist |
|---|---|---|
| The send-ignore globs are used to reject the files on the sending phase, and the list of the files included on the sending phase is used to exclude files from the fetching phase. | All the files are sent to the remote, and the fetch-ignore globs are used to reject files on the fetching phase. | The send-ignore globs are used on the sending phase, and the fetch-ignore globs are used on the fetching phase. |
Here is an example of what those file could be:
# Rejecting a specific file
data/cifar-10-python.tar.gz
# Rejecting any file in folders
results/*
batch/*
checkpoint/*
# Rejecting any files in a folder in any folder
*__pycache__/*
.git/*
Note that the send-ignore and fetch-ignore filepath can be set with respectively, --send-ignore and --fetch-ignore whose defaults parameters are .sendignore and .fetchignore.
Avoiding duplicate transfer
Runaway also allows you to get rid of redundant transfers, that may occur. For instance, imagine you run a runaway subcommand twice in a row, without changing the code. In this case, Runaway will probably send the same data twice. If your experimental data contains heavy binaries, that could take a few minutes or hours. Hopefully, we provide a way to reuse code that was uploaded before, by the mean of the --leave option, which can be either one of none, code, all. To understand how this option works, let us give a little more detail on the execution process.
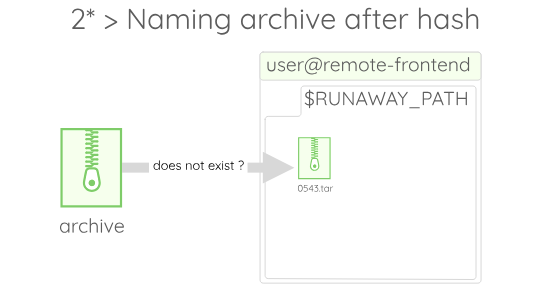
First, when the archive is created for the sending phase, an hash is produced out of the content of the archive:

Before sending the archive to the remote, Runaway checks in the $RUNAWAY_PATH if an archive named after this hash already. If no such archive exist, the code is sent, otherwise, the existing archive is used. The $RUNAWAY_PATH is set to the directory section of the profile at run-time, and is meant to store the code sent by your computer.
Finally when the execution is over, depending on the --leave option that is activated, the execution directory (here $RUNAWAY_CWD) and the archive can be deleted or not.
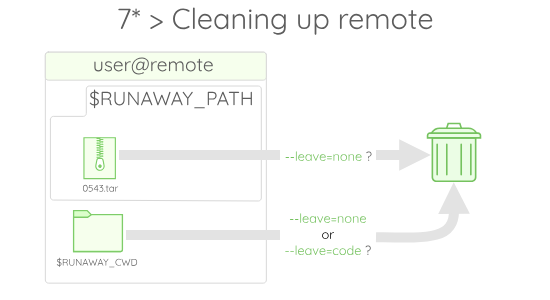
If --leave=all is activated both the archive and the execution folder are kept. If --leave=code is activated, the archive is kept and the execution folder gets deleted. Finally, if --leave=none is activated, both the archive and the execution folder are deleted.
By default, Runaway sets --leave=none to avoid filling your remote folders with data without you knowing. If you want your code to be reused to avoid duplicate transfer, just activate --leave=code !
Running on-local
For some reason, you may want to execute Runaway from the resource you actually target. That makes sense, for instance, if you want to execute Runaway on the frontend of a particular cluster, in order to let the runaway program run for a long period. In this case, there is no need to transfer the files to the remote.
In this case, you can use the --on-local flag on every sub-commands. When using this flag, the --remote-folders and --remotes-file option are ignored, and the --output-folders and --outputs-file are directly used.